
Thank you for visiting my theme! Replace this with your message to visitors.
Lighe field imaging is a kind of emerging imaging technology.
Reconstructing indoor light fields under complex illumination conditions is crucial for high-demand applications such as entertainment performances and sports events.

4D Light Field Segmentation from Light Field Super-pixel Hypergraph Representation
Xianqiang Lv, Xue Wang, Qing Wang, Jingyi Yu
IEEE TVCG, 27(9):3597-3610, 2021 (2020.03.20 online)
Paper |
Code |
BibTeX |
Github
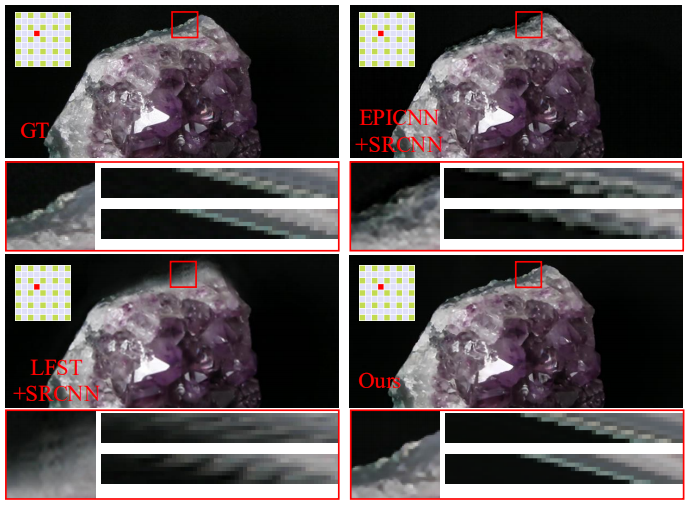
Revisiting Spatio-Angular Trade-off in Light Field Cameras and Extended Applications in Super-Resolution
Hao Zhu, Mantang Guo, Hongdong Li, Qing Wang
IEEE TVCG, 27(6):3019-3033, 2021 (2019.12.05 online)
Paper |
Code |
BibTeX |
Github

4D Light Field Superpixel and Segmentation
Hao Zhu, Qi Zhang, Qing Wang, Hongdong Li
IEEE TIP, 29: 85-99, 2020 (2019.07.15 online)
Paper |
Code |
BibTeX |
Github

Full View Optical Flow Estimation Leveraged from Light Field Superpixel
Hao Zhu, Xiaoming Sun, Qi Zhang, Qing Wang, Antonio Robles-Kelly, Hongdong Li, Shaodi You
IEEE TCI, 6:12-23, 2020 (2019.02.08 online)
Paper |
Code |
BibTeX |
Github

A Generic Multi-Projection-Center Model and Calibration Method for Light Field Cameras
Qi Zhang, Chunping Zhang, Jinbo Ling, Qing Wang, Jingyi Yu
IEEE TPAMI, 41(11):2539-2552, 2019
Paper |
Code |
BibTeX |
Github
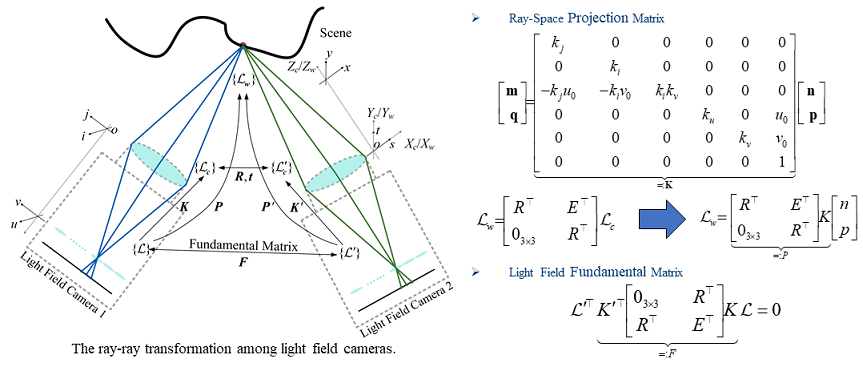
Ray-Space Projection Model for Light Field Camera
Qi Zhang; Jinbo Ling; Qing Wang; Jingyi Yu
CVPR 2019, Long Beach, USA, pp. 10121-10129, 2019.06.15-20
Paper |
Code |
BibTeX |
Github

Dense Light Field Reconstruction from Sparse Sampling Using Residual Network
Mantang Guo, Hao Zhu, Guoqing Zhou, Qing Wang
ACCV 2018, Perth, Australia, pp.50-65, 2018.12.01-05
Paper |
Code |
BibTeX |
Github

Occlusion-Model Guided Anti-occlusion Depth Estimation in Light Field
Hao Zhu, Qing Wang, Jingyi Yu
IEEE JSTSP, 11(7):965-978, 2017
Paper |
Code |
BibTeX |
Github
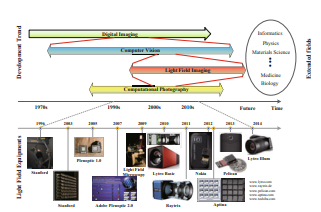
Light Field Imaging: Models, Calibrations, Reconstructions, and Applications
Hao Zhu, Qing Wang, Jingyi Yu
FITEE, 18(9):1236-1249, 2017 (2017.10.27)
Paper |
Code |
BibTeX |
Github
"The man can be destroyed but not defeated。" - Ernest Miller Hemingway